Introduction
The purpose of this blog is to demonstrate how to measure distance with the Kinect. The project uses Emgu (Computer Vision Library). Emgu is the C# version of OpenCV (Open Computer Vision). The following software example was taken from the Kinect SDK 1.8 Coordinate Mapping sample. The sample was modified to measure distance using the Depth Buffer.
How to take the Measurement
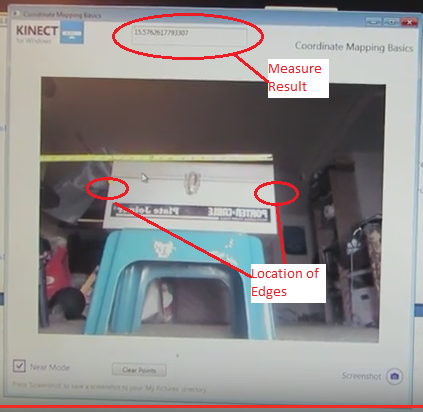
To measure the distance across the tool box, the user needs to collect 2 points as shown in the image. After the user has taken the 2 points, the result will show up in the top edit box as shown.
Theory of the operation
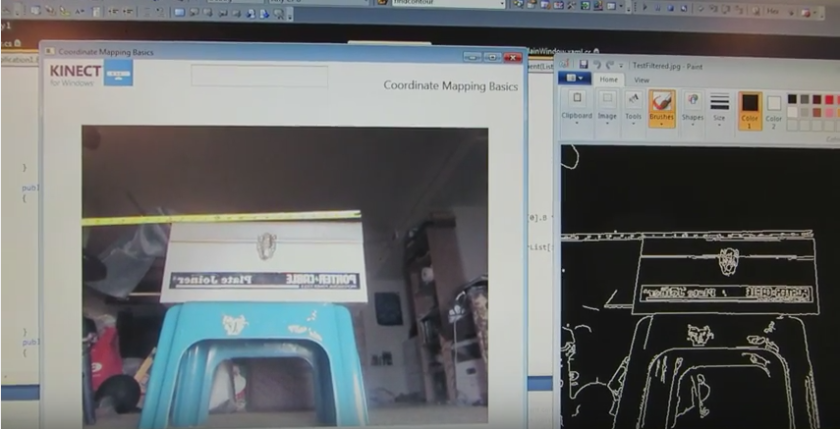 After the Kinect has collected the image, the software uses Canny Edge Detection to generate the edges of the object. The image on the right is the processed image after the Canny Edge Detector was applied.
After the Kinect has collected the image, the software uses Canny Edge Detection to generate the edges of the object. The image on the right is the processed image after the Canny Edge Detector was applied.
Edge Detection

The actual edge detection is done in the black and white image. To get the point on the edge;
- The user selects a line of pixels perpendicular to the edge know as the Region of Interest. This process returns an array of pixel intensities.
- The location of the edge occurs where the pixel intensity has the greatest difference between adjacent pixels. For example if the array returned { 0, 0, 0, 200, 10, 40 }. The location of the edge is where the intensity goes from 0 to 200.
C# Code for Calculating Distance
The code works by the user clicking the mouse button in the video window to get a point in the image. The mouse click returns the depthPoint from the image. The point is converted to a 3D space by mapping the point to a Skeleton point. After the user has attained 2 points, the distance between the points is calculated by the SQRT ((P1.x-P2.x)^2+(P1.y-P2.y)^2+(P1.z-P2.z)^2).
The following C# code shows the process of getting a point from the video and converting it to a 3d point.
{
DepthFormat,
this.depthPixels,
depthPoints);
DepthImagePoint depthPoint = new DepthImagePoint();
depthPoint.X = (int)depthPoints[af].X;
depthPoint.Y = (int)depthPoints[af].Y;
depthPoint.Depth = (int)depthPoints[af].Depth;
{
_sPoint1 = MapDepthPointToSkeletonPoint(DepthFormat, depthPoint); }
{
_sPoint2 = MapDepthPointToSkeletonPoint(DepthFormat, depthPoint);
{
distance = Math.Pow(_sPoint1.X – _sPoint2.X, 2) +
Math.Pow(_sPoint1.Y – _sPoint2.Y, 2);
Math.Pow(_sPoint1.Z – _sPoint2.Z, 2);
distance = Math.Sqrt(distance)*1000.0/25.4;
txtDistance.Text = distance.ToString();
}
References
A good reference for the project was “Beginning Kinect Programming with the Microsoft SDK” by Jarret Webb and James Ashley. The book is well written and has great examples. Chapter 8 “Beyond the Basics” has a lot of good utilities that were very useful. One example was converting between Bitmapsource and Bitmaps.
Limitations
The one limitation of the application; the results were not always consistent. Sometimes the edge detection did not detect the point, so you would need to take the point again. I am not sure if it is because the camera was not calibrated or the Depth and Image buffers were not aligned.